Understanding neural networks with neural-symbolic integration
People often conceive of Artificial Intelligence (AI) as a ‘black box’ because they find it difficult to understand the knowledge that is hidden inside it. They also find it difficult to understand the reasoning behind the choices that are made by AI. This understanding is required in many situations involving so-called ‘safety-critical’ tasks, such as autonomous driving. The decisions made by AI may have to be audited for insurance purposes, for greater accountability, or for legal challenges. Moreover, developers and engineers may need to understand these AI decisions so that they can fix them and prevent any potential negative outcomes.
Dr Joe Townsend, Dr Theodoros Kasioumis, and Dr Hiroya Inakoshi from the Artificial Intelligence Research Division at Fujitsu Research of Europe Ltd, explain that there are usually two approaches in response to this challenge. The first is ‘opening’ the black box in order to translate what is inside. The alternative involves training the AI model to be interpretable from the beginning. The researchers have developed solutions for both approaches for a type of machine learning paradigm called the Convolutional Neural Network (CNN). These two methods can also be deployed either separately or in unison.

Convolutional Neural Networks
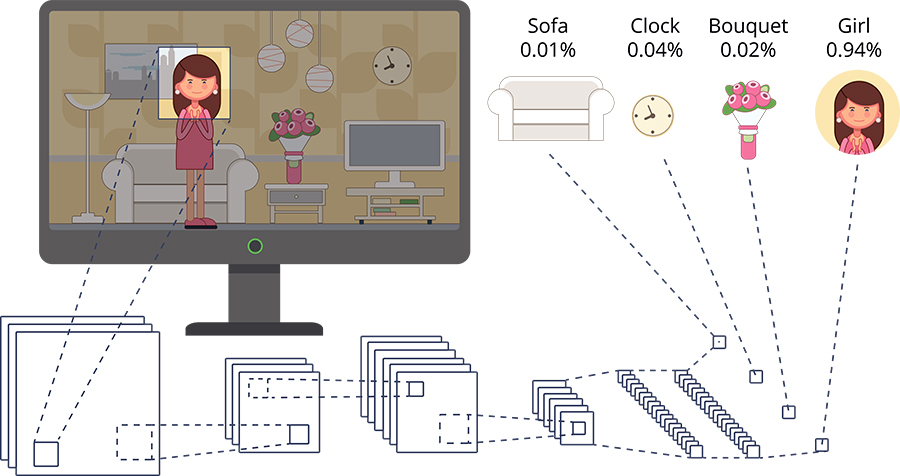
A CNN is a deep neural network that is designed to process structured arrays of data such as images. Artificial neural networks imitate aspects of both the structure and function of the human brain. In particular, CNNs are inspired by the visual cortex – the region of the brain that processes visual information. CNNs are great at picking up on patterns such as lines, gradients, circles, and even eyes and faces. This makes them highly suitable for image recognition tasks, where an image is processed by a series of layers that identify progressively more complex features. In CNNs, however, the information learned is distributed across millions of artificial neurons, making it very difficult to interpret.
CNNs are made up of layers, but the layers are not fully connected. They have filters in the form of sets of cube-shaped weights that are applied throughout the image (filters are often alternately referred to as ‘kernels’ or ‘feature detectors’). The filters are applied to the original image through convolutional layers and introduce parameter-sharing and translation invariance, so the same response is produced regardless of how its input is shifted. The convolutional layers contain most of the network’s user-specified parameters, including the number of filters, the size of the filters and the activation function.
Public concern regarding the extent to which AI can be trusted has led to increases in demand for trusted and explainable AI.
Trusted and explainable AI
Public concern regarding the extent to which AI can be trusted has led to increases in demand for trusted and explainable AI. Trusted AI implies that a decision made by an algorithm can be accounted for, is fair, and will cause no harm. Explainable AI is concerned with understanding and explaining how models trained through machine learning make their decisions, or how they might be designed or trained to be explainable from the outset.
Neural–Symbolic Integration
The field of Neural-Symbolic Integration concerns explainable AI for artificial neural networks, exploring ways of extracting interpretable, symbolic knowledge from trained networks, injecting such knowledge into those networks, or both. For example, if a neural network is trained to classify animal data, an extracted rule might say ‘if it has wings, it’s a bird’. However the developer might correct this assumption by injecting the fact ‘bats are mammals but have wings’ into the network.
ERIC: Extracting Relations Inferred from Convolutions
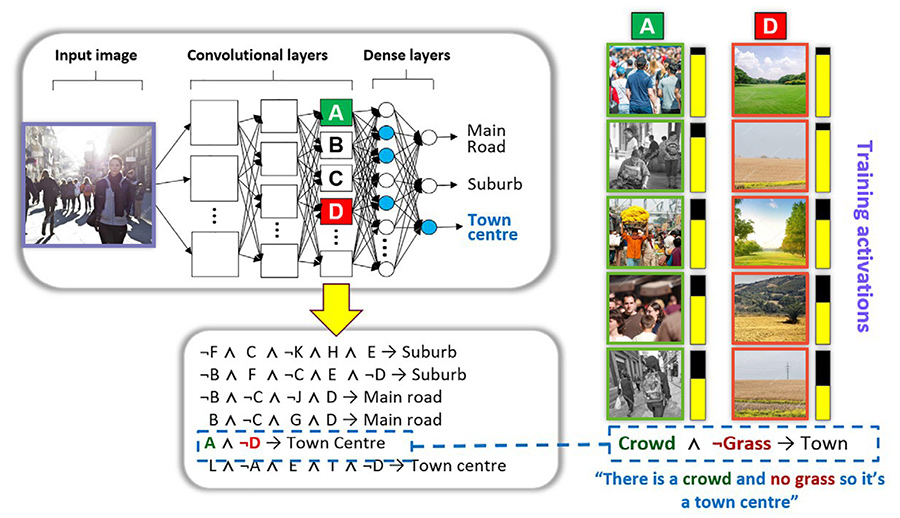
The research team has developed ERIC: Extracting Relations Inferred from Convolutions, a tool for ‘opening’ the black box. ERIC extracts the information that is distributed across the CNN and approximates it in a more digestible form. The information from various filters is mapped to symbols called ‘atoms’. Together these form rules that explain the network’s behaviour. These atoms and rules are equivalent to the words and sentences we use in our everyday language. Collectively, they form a logic program that can be used as a framework to further understand the behaviour of CNNs.
The researchers demonstrate ERIC’s capabilities by training a CNN to recognise different types of roads: desert roads, driveways, forests, highways, and streets. They carried out the task for a single convolutional layer and then again for multiple convolutional layers. Once they had extracted logic programs that approximated the CNN’s behaviour to a reasonable degree of accuracy, they visualised and labelled extracted atoms to interpret the meanings of individual filters. In addition, they show that the filters represent concepts that are specific to each individual type of road or shared between some of those types. They explain that interpreting the atoms is not always straightforward based on visual inspection. For example, it is not always clear what the set of images that a given filter activates for have in common, or two filters may activate for very similar concepts indistinguishable to the human eye. This has led them to develop Elite BackPropagation (below) to train the CNN so that it can learn ‘tidier’ representations that make rule extraction using ERIC simpler.

The researchers explain that when they extracted logic programs from multiple convolutional layers, these programs approximate the behaviour of the original CNN to varying degrees of accuracy depending on which and how many layers are included. Analysis of the extracted rules uncovered that the filters they represent correspond to semantically meaningful concepts. Moreover, the extracted rules represent how the CNN ‘thinks’. These experiments establish that filters can be mapped to atoms that in turn can be manipulated by a logic program and approximate the behaviour of the original CNN.
ERIC already provides a framework for discovering important symbols that have yet to acquire labels but can distinguish between classes.
Elite BackPropagation
The research team have developed another solution, Elite BackPropagation (EBP), that involves training the model to be interpretable from the beginning. EBP does this by enforcing class-wise activation sparsity – that is, by training CNNs to associate each category with a handful of ‘elite’ filters that rarely but strongly activate with respect to that category. Images from a specific class will, therefore, be associated with the same group of elite filters.
Considering the road classification task for example, a category of ‘highway’ images is associated with a small set of filters representing semantic concepts that are present on a highway, such as green traffic signs and cars. The researchers demonstrate how associating each category with an interpretable set of sparse neurons enables them to construct more compact rules that accurately explain the CNN decisions without a significant loss of accuracy. An example of one such extracted rule for the highway category could be ‘the image is a highway because there are green traffic signs and cars and no pedestrians’. Compact rules are more interpretable as there is less information for the reader to digest. These rules are in turn made up of building blocks comprising smaller sets of atoms. The atoms can then be reused in different combinations across the rule set and across different classes.
The researchers have performed quantitative comparisons of EBP with several activation sparsity methods from the literature, in terms of accuracy, activation sparsity and rule extraction. These reveal that EBP delivers higher sparsity without sacrificing accuracy. Furthermore, rules extracted from a CNN trained with EBP distil the knowledge of the CNN and use fewer atoms as well as having higher fidelity.
Future directions
Currently, even when using EBP the filters/atoms are labelled interactively and require manual inspection of the images they react to most strongly. The researchers aim to automate this process for both ERIC and EBP. This is likely to involve integrating existing methods for mapping filters to semantic concepts. These methods, however, have only finite sets of labels that were originally provided by humans with finite vocabularies. Knowledge-extraction methods may find new and important symbols which will require new words to be created. ERIC already provides a framework for discovering important filters that have yet to acquire labels but can distinguish between classes.
The research team are planning to explore ways of embedding rules into convolutional neural networks. This will enhance their interpretability and generalisation capabilities and is another goal of neural-symbolic integration more generally. This will be an important step towards bridging the gap between neural networks and symbolic representations.
Personal Response
What are the main challenges involved in automating the labelling process for filters/symbols in both ERIC and EBP?
Automatic labelling requires a labelling process that assumes a pre-defined set of labels or some other source from which to derive labels. There is no guarantee that any source has a label for the concept a given filter responds to, nor is there even any guarantee that any human language has a word for it!